
After 8+ years in web scraping, it was pretty obvious to test out how AI can help with large-scale data extraction. I was testing different approaches with LLM usage in web scraping, and my way of combining these two fields has changed a few times.
So how can AI help with web scraping? What should we do and what should we definitely avoid?
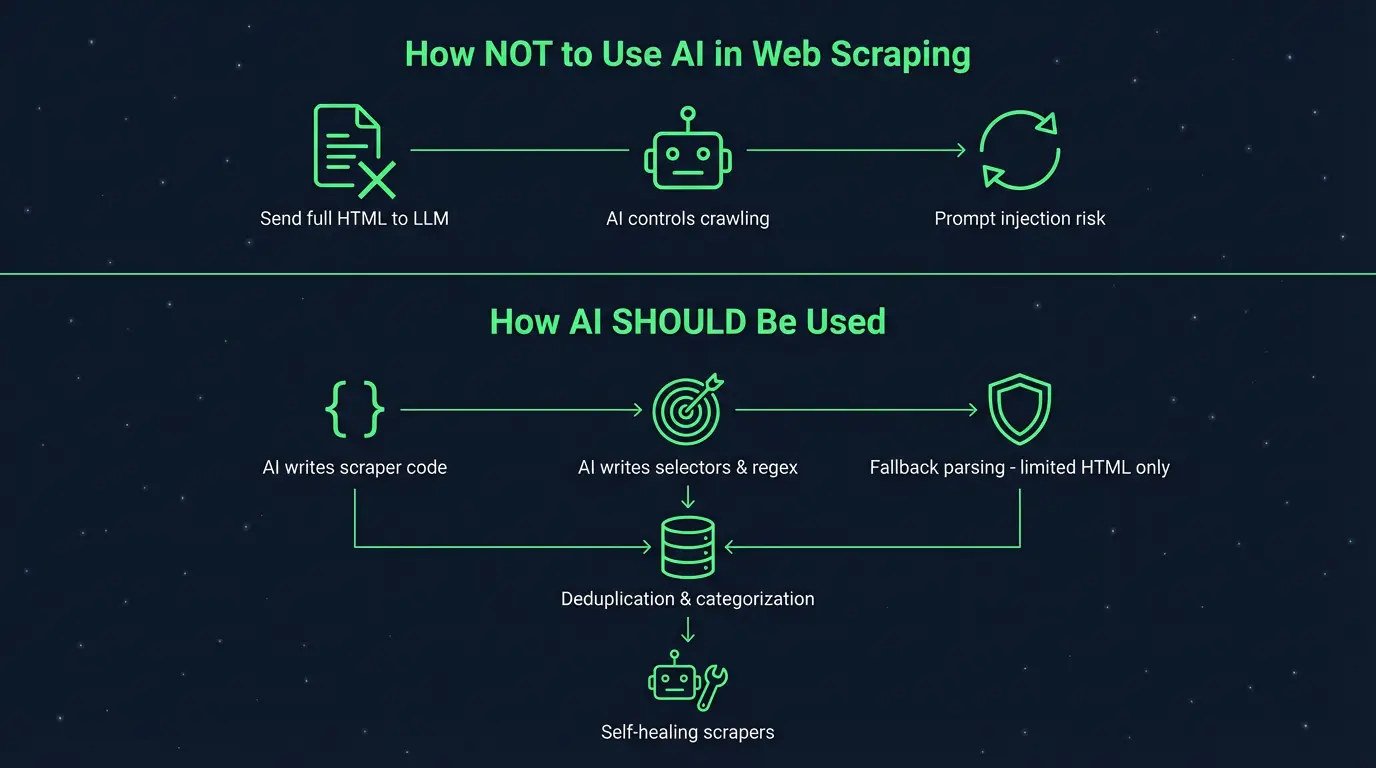
How NOT to scrape with LLM
I should start with how NOT to use AI for web scraping.
Parsing HTML with LLMs
First and most important: it’s a VERY bad idea to send HTML content to an LLM to extract data. This approach is wrong because:
- It’s super expensive.
- It’s not effective.
- It’s prone to hallucinations.
Of course, LLMs can be used to help parse HTML, but only in edge cases, not for every page you scrape.
Crawling process fully driven by AI agent
It’s usually also a bad idea to allow an AI agent to take full control of the crawling process. Of course, there are lots of use cases where running an AI agent with browser access is helpful. However, production-ready large-scale scraping is not one of them.
In most cases, websites that we scrape have a specific, well-defined link structure: pagination, categories and subcategories, etc. In such cases, using an LLM to decide what to crawl next is overengineering, as simple regex is more than enough. And since scraping usually involves a great number of pages to crawl, we should save as much money as possible, as there will be other things we need to pay for.
LLMs in charge of crawling can also be prone to prompt injections aimed at getting scrapers stuck in an infinite loop or trapped in a honeypot for distinguishing humans from bots. Of course, with good prompt engineering we can minimize the possibility of such situations, but we’ll never fully protect against them.
However, there are a few use cases where this strategy can actually be useful.
So how can AI be used in real-world web scraping?
How AI can help with web scraping and web crawling
Writing code with AI
AI is great at producing code, so we should take advantage of it in web scraping too. Agentic coding tools like Claude Code, Codex, or Cursor can help with boilerplating scraper code, adding new functionalities, adding integrations with databases or other services. It’s really helpful since dealing with clients’ scrapers requires using different integrations.
Writing selectors and regex with AI
What’s more, AI is also amazing at writing selectors. Whether it’s CSS selectors, XPath, or regular expressions, AI will write them for you. Just provide it with an example snippet of HTML code from a website and instantly you’ll have a good selector. Let’s be honest: who would write regex without AI now?
Automatic data extraction as a fallback
I’ve encouraged you NOT to parse HTML with AI in the normal scraping process. However, it’s worth considering doing it as a fallback when your normal parsing fails.
Sometimes data is presented in a different way on some pages. If a developer hasn’t seen such a case before, the typical selectors approach will fail here. In such scenarios, using an LLM to parse data can be an option to consider. However, in order to keep it robust and reduce costs, there are a few rules to follow:
- Never give the entire HTML to an LLM. Remove
<head>, remove all the scripts, header, and footer. If possible, extract only the block of code where data can be hidden, e.g., extract a single div that’s a product tile. The less HTML, the better. - Use cheaper AI models. For parsing HTML you don’t need Opus 4.6. Try the cheapest one, consider small open-source models that can eventually be self-hosted to reduce costs.
- Use structured output from the LLM. Data needs to be accurate. Make sure the LLM extracts only the required things, and if it’s not sure, it should use nulls to represent missing (or unclear) values.
This approach should still be treated as experimental. We can’t always trust LLMs in such tasks and we should always verify them. However, sometimes it’s better to have something rather than nothing.
I strongly recommend also keeping the original HTML in such edge cases.
Categorization and deduplication
LLMs can be helpful not only for web scraping or the crawling process but also in data sanitization, which is one of the most important parts.
One of the biggest issues with large-scale scraping is deduplication. Sometimes it’s very hard to code a reliable way of verifying if two products are the same or just similar. And LLMs can help here a lot.
Well-defined prompts with pretty decent models are giving great results with deduplication.
AI agents scraping for edge cases
Sometimes data on a website is not structured at all. Or we need to scrape data mentioned in text indirectly. Or we just need to get data quickly with no time to develop scrapers.
For such cases, it’s worth considering using an AI agent with browser control to scrape the data for us. This strategy is not scalable and can be very expensive, but an LLM armed with browser tools, certain skills, and context understanding allows you to quickly scrape data that typical scraping without AI would take a lot of time or would be impossible.
AI agents can easily understand mentions in text, have a defined context on what we need to scrape, and can make decisions that move the extraction forward.
What’s interesting: some agent bots would just normally click the “I’m not a robot” button like it wasn’t something special.
When you want to use this strategy, keep in mind that it will be very experimental and can easily get expensive. Always try to write the scraper the more classical way first.
Self-healing and self-adaptive web scrapers
This is the most exciting strategy for using AI in web scraping.
One of the biggest issues with scrapers is handling website changes and errors (often caused by page structures not spotted before). It’s really hard to spot such situations and it sometimes requires a lot of work to fix or even adjust the code.
And LLMs can really help here.
Let’s define the process of how self-healing and self-adapting scrapers can work:
- Scraper logs and error traces can be passed to AI (for example via MCP) for analysis.
- The LLM can spot the error or website change.
- The AI agent enters the website, checks logs, code, and recent website code.
- In case a scraper fix/adjustment is needed, the AI agent creates a task for agentic coding tools like Claude Code/Codex.
- The agentic coding tool creates a PR with adjustments for scrapers.
The best results of such a strategy would require setting up an environment allowing you to test implemented changes on a smaller scale.
Conclusion
While most AI strategies for scraping are currently more in an experimental phase or are used for fallbacks and covering edge cases, it’s still worth trying to implement them in web scraping software.
Kamil Kwapisz
Working on something similar? Let's talk.
Book a free call →